Performance results first
GradICON, Constricon can do a great job solving the challenging retina registration problem. (Here we use the Constricon approach)
Constricon:
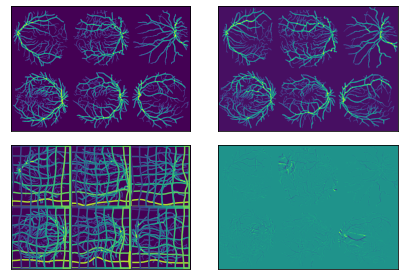
In the event that the moving and fixed images are misaligned by a constant shift, ConstrICON can manage it with careful hyperparameter settings
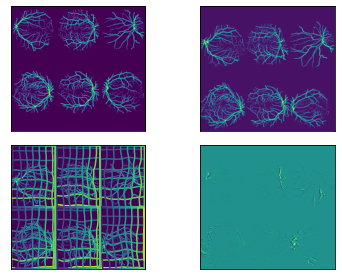
Where GradICON just fails

The new equivariant architecture can't see the shift, so it works fine whether or not the images are shifted
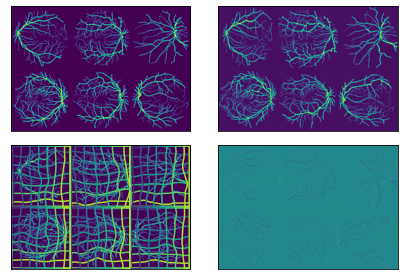
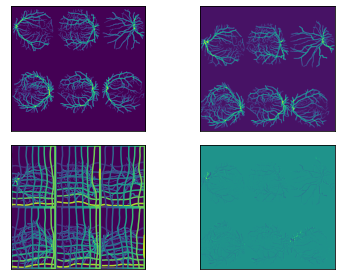
Equivariant architecture details
For the first breakthrough, we need to cover a proof first.
Assertion: if is equivariant to transforming (henceforth [W, U] equivariant) and is equivariant to transforming (henceforth [U, U] equivariant) for U and W from a class of transforms , then is equivariant
Proof:
This allows the use of powerful but only [U, U] equivariant algorithms such as Voxelmorph-like approaches to be integrated into a [W, U] equivariant pipeline.
For our registration approach, we will use
where are standard registration U-Nets that are naturally [U, U] equivariant.
Tuning details
For this experiment, we target [W, U] translation equivariance.
To make this train end to end, we made several fine adjustments to equivariant_reg.
We normalize the feature vectors before passing to the attention layer, and then scale by 4.
We use a simple convolutional network for featurizing with residual connections and no downsampling. We pad the image before processing, and crop afterwards, to remove boundary effects. This is exactly translation equivariant to 1 pixel shifts.
We add batch normalization to the feature extraction network.
We use diffusion regularization on the end to end registration pipeline. GradICON or bending energy regularization work for fine tuning, but require student-teacher initialization and cannot train from scratch. For medical images, it is very important to simplify the training process, so eliminating the student-teacher initialization is a massive win.
We use 128 dimensional feature vectors. 64 dimensions is too little.
Notebooks
constricon_noshift constricon_shift gradicon_shift equicon_noshift equicon_shift
Back to Reports