Problem: No scale equivariance in real lungs
As a result, the transformer only captures translation
just transformer:
overall pipeline:
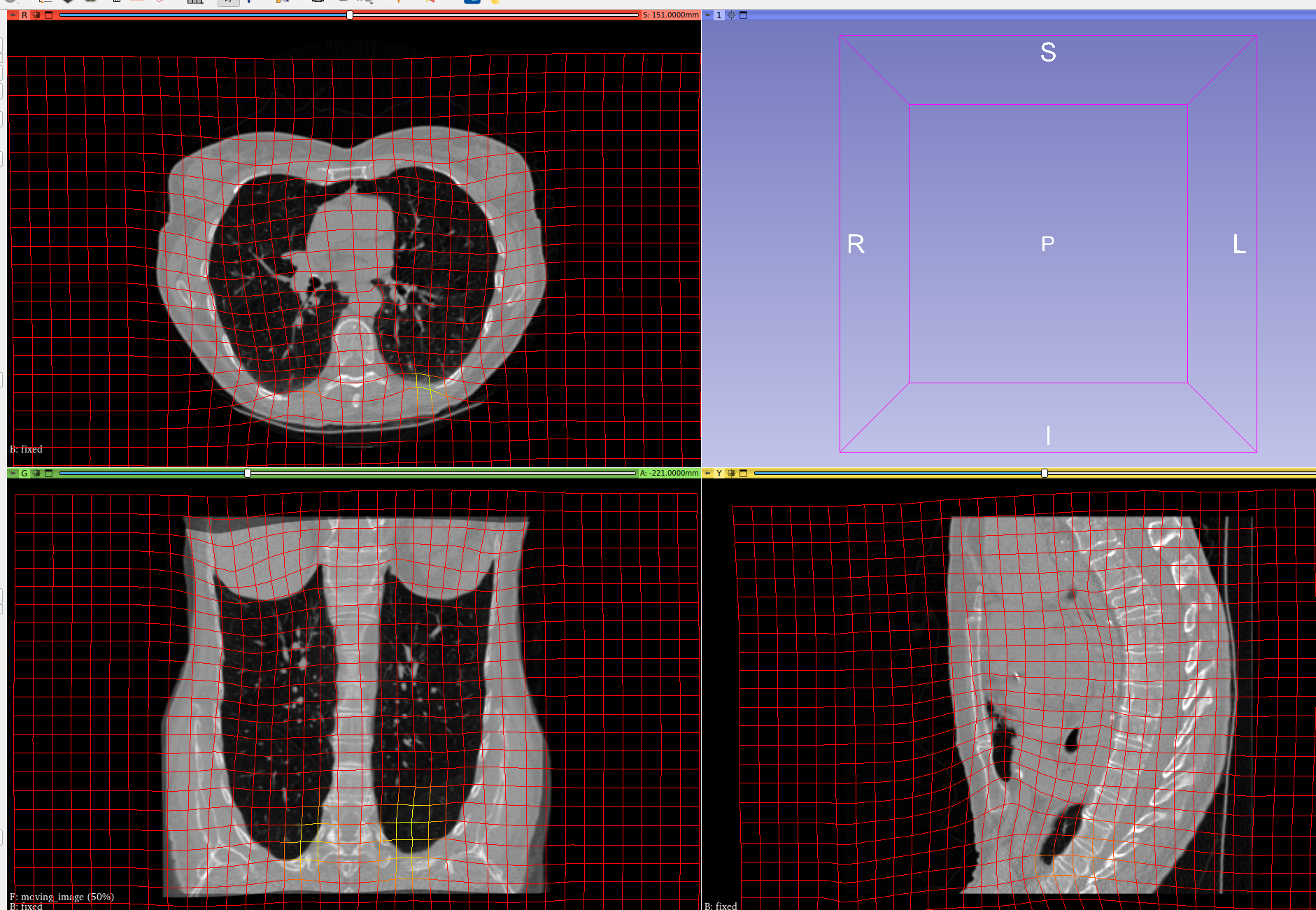
The poor performance is coming from the entire non-translation transform being handled by the gradicon part.
Tactic: Create a 2D example of the problem
We warp, shift, and also scale retina segmentations by 80%. As a sanity check, we throw ConstrICON at this problem.
Just 80% scale, ConstrICON can do:
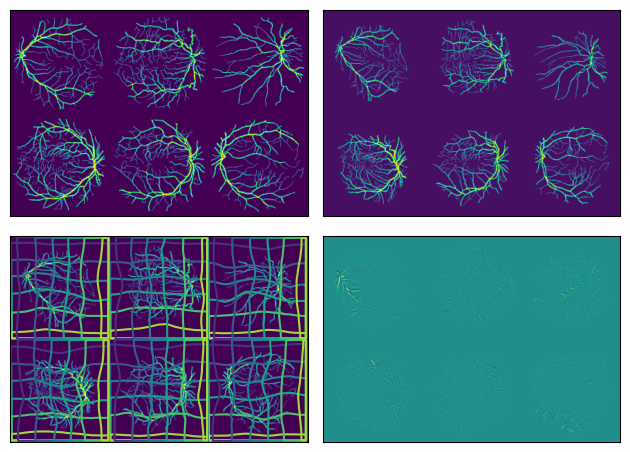
However, with the scale and shift, ConstrICON cannot converge:

Prediction: EquICON will capture the translation in the transformer, but will leave the scale to the displacement prediction layers, like we saw in the lung.
Experiment Result:
Our prediction was wrong. In 2d, the transformer layer captures the scale, only leaving local variations for the displacement layer. Therefore, we do not yet have a toy model.
End to end result:

Just Transformer:
Solutions:
I am hesitant to start trying solutions to the lung scale problem in 3d without a 2d model, but will do so if necessary.
Once we can get a toy model, there are two solutions to test in 2d. Once is the magnitude penalty on the GradICON layers that we discussed earlier. As long as the GradICOn layers can capture the scale, then this penalty will shift it, once captured, onto the transformer layer.
return (self.phi_AB, self.lmbda * inverse_consistency_loss
+ torch.mean(10000 * (self.phi_AB(self.identity_map) - self.identity_map)**2))Does this work in the 2-D case?
Solution 2: more equivariance.
The canonical way to get scale "Equivariance" is to run the image through the same network at multiple scales and sum (citation citation). Does this help?
Solution 3: The 3d code is buggy.
The way to fix this, if it's true, is to read the 3-D code until I see the bug? Hasn't worked so far.
Marc suggestions:
Weaker 2d feature extraction
Try retina using 3d code
3D circles and squares
White noise to 2d case
Write up a MONAI integration timeline
Back to Reports